
In its recent policy update, tech giant Google has decided to gather data from all sources available on the internet to train its AI models, including Bard.
Under the new policy, Google will be able to collect data from a variety of public sources, including social media posts, government records, and the web. This data will be used to train AI models for a variety of purposes, such as spam filtering, fraud detection, and language translation.
Google argues that using public data is necessary to train AI models that are accurate and effective. The company also says that it will take steps to protect user privacy, such as de-identifying data before it is used to train models.
The Google Policy page states: “We may share non-personally identifiable information publicly and with our partners — like publishers, advertisers, developers, or rights holders. For example, we share information publicly to show trends about the general use of our services.”
What is Google’s New Policy?
Google's policy on collecting public data is not very transparent, so users must read the policy carefully to understand what information Google collects.
Here is what the policy update mentions, “Google uses information to improve our services and to develop new products, features, and technologies that benefit our users and the public.
“For example, we may collect information that’s publicly available online or from other public sources to help train Google’s AI models and build products and features like Google Translate, Bard, and Cloud AI capabilities. Or, if your business’s information appears on a website, we may index and display it on Google services”, it added.
Earlier the company was using this information to update and train its language models which enhanced its already available products such as Google Translate. Now, the company has clearly mentioned that all the public data will be used to update its AI products.
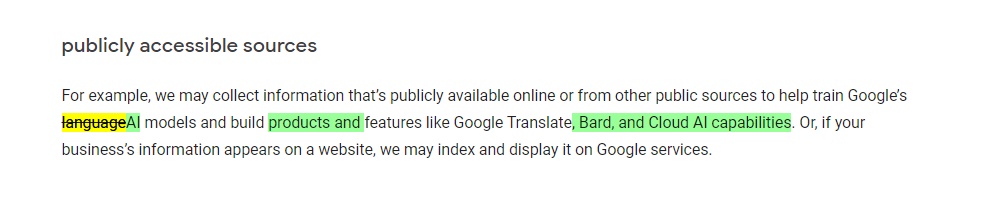
Source: Google
The above image is from Google’s policy archives in which the green colour represents newly added information.
The Dangers of Data Scraping
This new policy update can cause severe cases of data scraping and privacy concerns. While companies typically keep user data confidential for future use and new product development, Google's new policy allows the company to use any publicly available information to train its AI models.
This means that Google can access and process any type of data that is available on the internet, including personal information. The company has mentioned that it de-identifies the sources but it can still be a trouble.
First, it can violate the privacy of individuals. When data is scraped without permission, individuals may not be aware that their data is being collected or how it is being used. This can lead to a number of problems, such as identity theft and financial fraud.
Second, data scraping can be used to create biased AI models. If AI models are trained on data that is scraped from the internet, the models may reflect the biases that are already present in the data. This can lead to AI models that discriminate against certain groups of people.
Finally, data scraping can disrupt the internet. The most recent example of this is the Twitter outage. When data is scraped from websites, it can slow down the websites and make them difficult to use.
Elon Musk displayed his concerns about data scraping and he decided to limit the number of tweets that people can read per day he is also continuously working to make the platform more secure by monetising different services.
In conclusion, the new policy can surely help Google generate powerful AI but it will be a safety hazard as well. The policies could also lead to increased data scraping and privacy violations. It is important to carefully monitor how Google implements these policies.




-1765956461168.jpg)

Comments
All Comments (0)
Join the conversation